
The Infrastructure of Integrity: Architectural Licensing, Technical Provenance, and the Systematic Resolution of Ethical Dilemmas in Generative Artificial Intelligence
From "Black Boxes" to the Infrastructure of Integrity: Why AI Needs a New Architecture


The rapid proliferation of generative artificial intelligence has moved past the initial phase of technological wonder into a period of profound institutional and ethical re-evaluation. At the centre of this transition lies a fundamental conflict between the traditional frameworks of intellectual property and the novel capabilities of machine learning systems to ingest, synthesise and replicate human creative expression at an industrial scale. The integration of licensing protocols directly into the architecture of artificial intelligence systems represents a transformative strategy for resolving the ethical tensions currently plaguing the industry. By embedding mechanisms for clear attribution, real-time compliance and fair compensation into the very fabric of creative tools and model training pipelines, the technology sector can move toward a sustainable ecosystem that respects human authorship while fostering innovation.[1, 2]
The ethical challenges posed by artificial intelligence are not merely a continuation of past copyright disputes but a qualitative shift in how digital systems interact with human culture. The traditional “notice-and-takedown” regime of the Digital Millennium Copyright Act (DMCA) is increasingly viewed as an insufficient tool for the era of Large Language Models (LLMs) and diffusion-based image generators, which operate as “black boxes” that often obscure the origin and lineage of the data they consume.[3, 4] Consequently, the call for “compliance-by-design”—where rights management is not an afterthought but a foundational component—is gaining momentum among creators, legal scholars, and technology developers alike.[5]
The Historical Transformation of Creative Control: The Music Industry Precedent
To understand why embedded licensing is a critical solution for artificial intelligence, one must analyse the previous structural transformation of a creative industry: the music industry’s transition from physical media to streaming services. This shift provides a vital historical mirror, illustrating how changes in distribution architecture can fundamentally reorder power dynamics, revenue models, and the concept of ownership.[6, 7]
From Scarcity to Ubiquity: The Gatekeeper Re-Intermediation
In the pre-streaming era, the music industry was defined by a model of physical scarcity. Record labels, radio stations, and physical retailers acted as the primary gatekeepers, controlling the flow of music to the public through manufacturing and distribution networks that were capital-intensive and geographically limited.[7, 8] The introduction of subscription-based platforms like Spotify, Apple Music and Amazon Music fundamentally altered this control over distribution by moving the industry from a unit-sales model to an access-based model.[6, 9]
The transformation was not merely about convenience; it was a comprehensive reorganisation of the value chain. While digital technology theoretically allowed for a “direct-to-consumer” model, the reality was the emergence of new, “unavoidable” intermediaries.[10] These new gatekeepers include third-party digital distributors like DistroKid and TuneCore, which creators must use to access major platforms, as well as Collective Management Organisations (CMOs) that serve as mandatory conduits for licensing and royalty administration.[10]
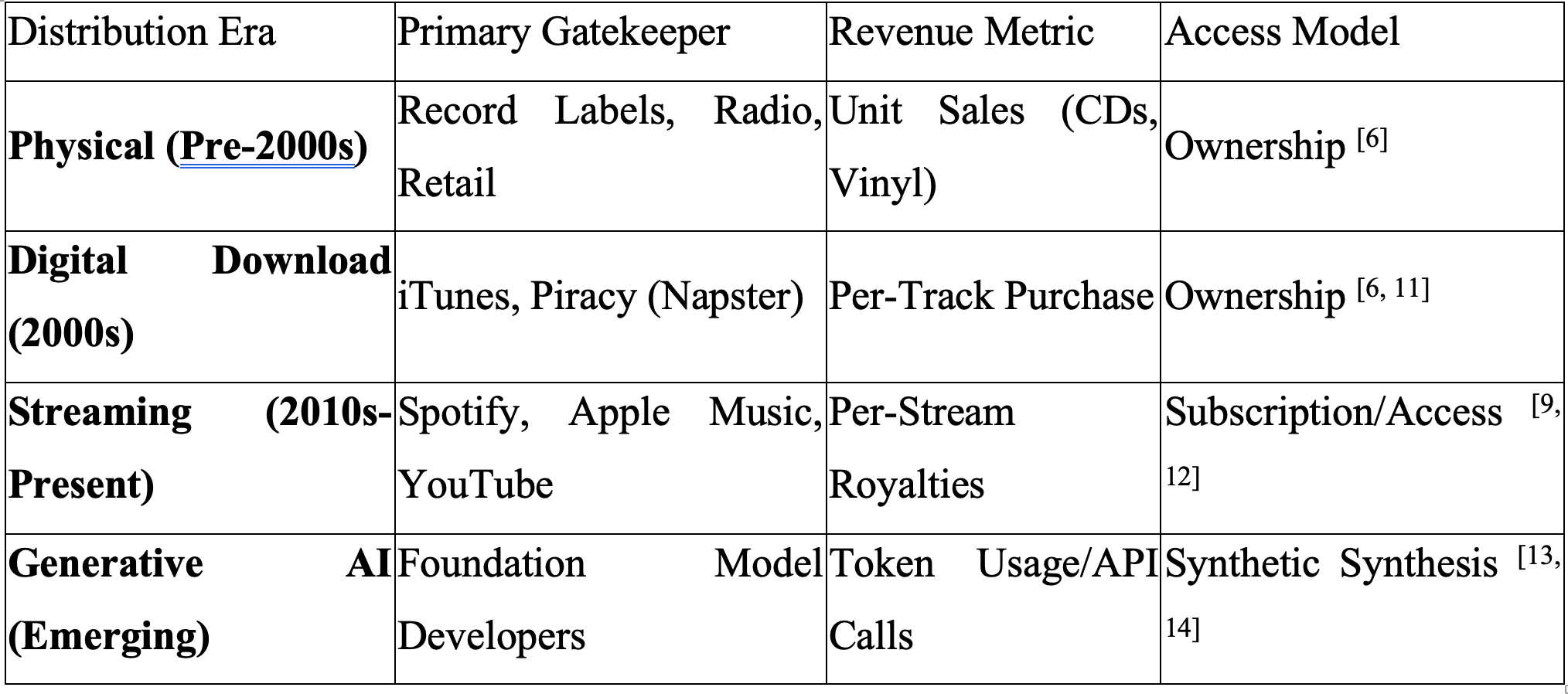
The “Value Gap” and the Economics of Consumption
The subscription model significantly impacted industry revenue, initially through the cannibalisation of traditional sales and later through a massive increase in the total number of paying users. By the end of 2024, streaming represented roughly two-thirds of global recorded-music revenues, with subscription streaming alone exceeding 50%.[8, 9] However, this growth has been accompanied by a controversial “value gap.” Although overall industry revenue has benefited from streaming, individual artists’ portions have frequently shrunk, with royalties dipping as low as fractions of a cent per stream.[11, 12]
Control has shifted from label-driven marketing to data-driven algorithmic curation. Features like Spotify’s “Discover Weekly” or “New Music Friday” now dictate which tracks receive attention. A song ranked number one on a major curated playlist can gain an average of 20 million additional streams, illustrating the platform’s enormous influence over cultural discovery.[15] This algorithmic gatekeeping presents a “winner-take-all” distribution of wealth, where a small fraction of “stars” capture the majority of the market, a trend that generative AI systems risk exacerbating if they are not governed by transparent licensing frameworks.[8]
The Authorial Crisis: AI vs. Historical Copyright Challenges
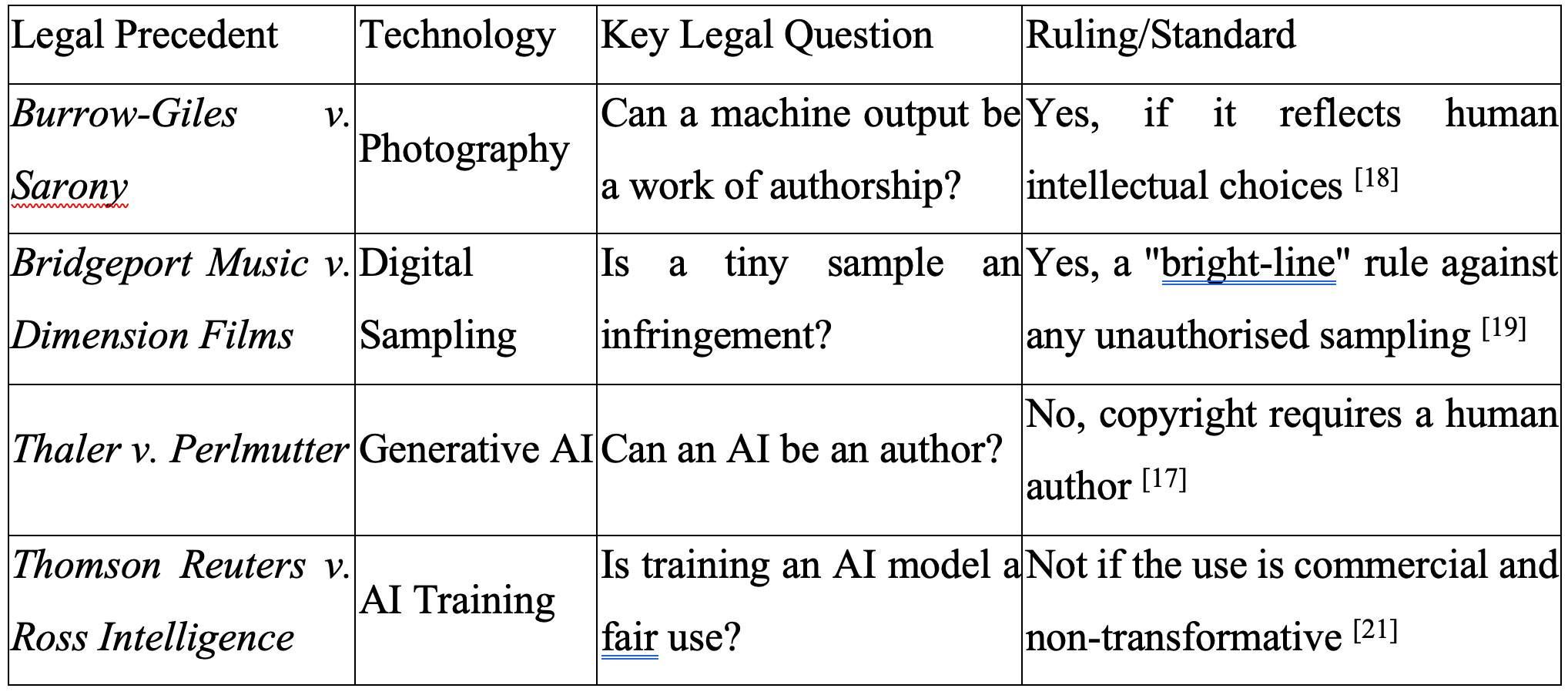
The impact of artificial intelligence on authorship is fundamentally distinct from previous technological shifts, such as the introduction of photography or the practice of digital sampling. While earlier innovations offered new tools for human expression, generative AI challenges the legal and philosophical definition of the “author” by automating the expressive choices that were previously the exclusive domain of human creativity.[16, 17]
The Camera Analogy and the Limits of Mechanical Assistance
In the 19th-century case Burrow-Giles Lithographic Co. v. Sarony, the U.S. Supreme Court established that a photograph could be copyrighted because it reflected the photographer’s “intellectual conceptions.” The camera was viewed as a tool that facilitated human expression through choices in lighting, framing, and arrangement.[17, 18] Current legal guidance in the U.S. and the EU attempts to apply this analogy to AI, distinguishing between “assistive use” and “stand-in for human creativity”.[16]
However, the “Creativity Machine” case (Thaler v. Perlmutter, 2023) underscored the limits of this analogy. The court ruled that an image generated autonomously by an AI system without meaningful human input is ineligible for copyright protection, as the law requires a human “person” to be the author.[17] This creates a “grey zone” for AI-generated works: while simple prompts do not qualify as authorship, a human who significantly modifies, arranges, or edits AI-generated material may still claim protection for the final work.[16, 18]
Digital Sampling and the Technical Logic of “Up-Sampling”
Digital sampling in music provided a previous challenge to copyright, centring on the reproduction of specific sound recording fragments. Legal standards developed into two primary forks: the Sixth Circuit’s “bright-line” rule, which prohibits any unauthorised sample regardless of its length, and the Ninth Circuit’s “substantiality” test, which allows for de minimis uses that a listener would not recognise.[19, 20]
Generative AI, however, does not sample in the traditional sense; it “up-samples.” Models like OpenAI’s Jukebox ingest thousands of copyrighted songs and compress the audio data into finely encoded segments to extract patterns and structures. Models like this compress audio into discrete representations during training and learn statistical structure; outputs are generated from learned parameters and may ‘resemble’ training styles or passages, but are not best characterised as an assembled ‘tapestry’ of sound-recording fragments.[19] This process arguably infringes on the reproduction right under 17 U.S.C. § 106(1), as the resulting audio is manipulated from the actual works used in training rather than being an entirely new creation.[19]
Solving Ethical Issues through Embedded Licensing
The integration of licensing into AI systems addresses several core ethical dilemmas: the lack of attribution, the difficulty of real-time compliance, the absence of fair compensation, and the risk of cultural misappropriation. By moving from an “opt-out” to an “opt-in” licensing system, the technology sector can rebuild trust with the creative community.[4, 22]
Clear Attribution and Technical Provenance
One of the primary ethical complaints regarding generative AI is the “erasure” of the original creator. When a model generates an image “in the style of” a specific artist, it often does so without any metadata linking back to the human who developed that style. Integrating the Coalition for Content Provenance and Authenticity (C2PA) standard allows for the creation of “Content Credentials” that are cryptographically bound to a digital asset.[23, 24]
These credentials record the entire provenance of a piece of content, including when and where it was created, how it was modified, and whether AI tools were used in the process.[23]
Because the C2PA Manifest is digitally signed, it provides a tamper-evident history that ensures creators receive credit for their work, even as it moves across different platforms and applications.[23, 24] This addresses the problem of “opacity” in AI systems, providing the transparency required for ethical governance.[3]
Real-Time Compliance and “Policy-as-Content”
Traditional copyright enforcement is reactive, occurring long after the infringement has taken place. Embedded licensing allows for real-time compliance through the integration of the W3C Open Digital Rights Language (ODRL). ODRL enables the creation of machine-readable semantic policies that define usage conditions—such as fees, geographical restrictions, and the number of permitted uses—directly within the content’s metadata.[5]
This “compliance protocol stack” creates a closed-loop system where a platform can automatically monitor usage and freeze violations based on the uploader’s requirements.[5]
By mapping these event streams to the “Notify-Remove-Counter-Notify” legal process of DMCA §512, developers can ensure that their systems are always in compliance with the law, thereby reducing the risk of costly legal disputes.[5]
Fair Compensation through Micro-Licensing and Blockchain
The current model of AI training and deployment often resembles a “free rider” economy: developers extract value from vast corpora of copyrighted or otherwise valuable cultural material while attribution and compensation are either absent or operationally impractical at scale.[22, 25] Embedded licensing enables an alternative settlement layer—usage-based remuneration—where value flows to rights-holders in proportion to actual consumption (training ingestion, fine-tuning, and/or inference-time utilisation), rather than being captured exclusively by downstream model operators.[13]
In practical terms, micro-licensing is most credible when it is implemented as a metered, machine-readable workflow rather than a contractual abstraction. A model or platform can (i) read the applicable usage conditions (for example via ODRL-style policies), (ii) verify provenance/entitlements (for example via C2PA-style credentials), and (iii) record usage events in an auditable ledger.[5, 23, 24] Where the system calls a model through an API, the usage event can be quantified (request type, tokens, outputs, jurisdictional constraints) and mapped to a tariff—triggering an automated payment to the relevant rights-holders.[13, 14] Blockchain-based smart contracts are one possible mechanism for this settlement, but the core requirement is not “crypto” as such; it is an enforceable, transparent, and low-friction accounting layer capable of handling high-volume, low-value transactions.[13]
Strengthening compensation is also strategically relevant to model quality and sustainability. A growing body of research warns that, as synthetic content proliferates online, subsequent generations of models are increasingly likely to be trained on model-generated data—creating a recursive feedback loop in which diversity diminishes and low-probability “tails” of the original distribution disappear. This phenomenon—described as the “curse of recursion” and formalised as “model collapse”—has been demonstrated across generative model families, including language models and is framed as a systemic risk where synthetic data “pollutes” future training sets.[41, 42]
In that context, licensing is not a silver bullet; however, it materially supports two mitigation pathways: (i) preserving incentives for humans and institutions to continue producing and curating high-quality original content, and (ii) improving dataset hygiene by making provenance signals, permissions, and exclusions operationally legible (so that synthetic or unauthorised inputs can be identified and filtered, rather than silently absorbed into training pipelines).[23, 24, 41, 42]
Accordingly, micro-licensing should be presented not only as an ethical remedy for value capture, but also as infrastructure that helps maintain the long-run integrity of the data supply on which frontier models depend—aligning creator economics, compliance, and technical sustainability in a single design pattern.[13, 22, 41, 42]
Cultural Preservation and Preventing Misappropriation
The preservation of cultural heritage, particularly for Indigenous and marginalised communities, is a critical ethical imperative. AI systems often harvest cultural data—such as traditional designs, languages, and stories—without the consent of the source communities, leading to what some scholars describe as “digital colonialism”.[2, 26]
A cultural rights approach to AI digitalisation emphasises community consent as a “non-negotiable pillar”.[27] Licensing models that require AI developers to obtain formal agreements before using cultural data can prevent unauthorised commercial exploitation, such as the widely criticised use of the Zia symbol or Navajo branding without tribal permission.[26, 27] Furthermore, AI-powered platforms can be trained on culturally specific datasets that respect the authority of guardian communities, ensuring that digitalised heritage is represented authentically and not distorted or misused.[27]

Embedding Rights Management into Creative Tools
Embedding rights management directly into the tools used by creators—such as cameras, editing software, and AI interfaces—improves copyright enforcement by creating a “trusted chain” from the moment of inception.[5, 28]
Forensic Watermarking and Persistence
One of the primary challenges of digital copyright is that metadata is easily stripped. To counter this, technologies like Steg.AI use forensic watermarking to embed unique, invisible identifiers directly into the pixels of an image or the frames of a video.[29, 30] These watermarks are “tamper-resistant,” meaning they survive edits like cropping, compression, and even screenshots.[29, 30, 31]
When these watermarking tools are integrated into Digital Asset Management (DAM) systems, every shared version of an asset receives a unique forensic fingerprint. If a leak or unauthorised use occurs, the watermark can be extracted to identify the specific source or licensee, turning uncontrolled distribution into an attributable workflow.[28, 32] This integration represents a “proactive” rather than “reactive” solution for content safety.[29]
Hard and Soft Bindings in Content Credentials
The C2PA specification uses both “hard” and “soft” bindings to ensure that content credentials remain attached to an asset throughout its lifecycle. A “hard binding” is a cryptographic hash that links the C2PA Manifest to the asset’s digital content. If the content is changed by even a single bit, the hash will no longer match, and the credential will be flagged as invalid.[23, 24]
“Soft bindings” enhance the durability of these credentials by enabling the discovery of the manifest even if it is removed from the file. This is often achieved through the use of an invisible watermark that serves as a key to look up the manifest in an external repository.[23, 33] This dual-layer approach ensures that provenance is maintained even when content is modified or moved across different file formats.[33]
The Role of Certification: Fairly Trained Models
The emergence of organisations like “Fairly Trained” provides a framework for identifying AI models that respect creators’ rights. These organisations certify models that are not trained on copyrighted work without permission, providing a “marker” for companies and consumers who wish to support ethical AI.[22, 34] Certification helps counter the industry’s opacity by ensuring that companies meet rigorous ethical standards for data procurement.[34]
As more models become certified, creators are encouraged to use only those systems that respect their rights, creating a market incentive for developers to adopt “fairly trained” protocols.[22] This move toward certified, licensed datasets is viewed as an “important step” toward reinforcing the principle that rights-holder consent is necessary for generative AI training.[22]
The 2025 Legal Landscape: Fair Use and the Licensing Market
Recent judicial decisions in 2025 have significantly impacted the debate over whether training AI models on copyrighted data constitutes “fair use.” These cases illustrate the growing legal pressure for developers to adopt formal licensing arrangements.[21, 25]
Transformativeness vs. Market Substitution
In the landmark case Thomson Reuters v. Ross Intelligence, the court ruled that the unauthorised use of copyrighted Westlaw editorial headnotes to build a competing legal research product AI product was not “fair use.” The court focused on the fact that the AI tool directly competed against the copyright owner’s offerings, thereby affecting the potential market for the work.[21] This ruling signals that courts are less likely to find fair use when the AI system serves as a substitute for the original work.[25, 35]
Conversely, in cases involving the training of Large Language Models, some judges have found the process to be “exceedingly transformative”.[36, 37] Judge Alsup in the Anthropic case (2025) likened AI training to the human act of reading books to learn how to write. However, he drew a sharp distinction between the act of training and the act of building a “central library” using pirated books. While the training might be transformative, the possession and storage of pirated material for the purpose of avoiding legitimate purchase were deemed infringing.[36, 37, 38]
The Impact on the Licensing Market
A critical factor in the “fair use” analysis is the effect of the use on the “potential market” for the copyrighted work. The U.S. Copyright Office (USCO) has argued that where licensing options exist or are likely to be feasible, developers should be encouraged to use them rather than relying on fair use.[25, 39] The emergence of data licensing marketplaces—where publishers, image banks, and other rights holders can sell access to their catalogues—undermines the argument that mass scraping is a “reasonably necessary” fair use.[1, 25]
The USCO report on AI ‘copyrightability’ emphasises that if a model is trained to produce content that “shares the purpose” of the original work (e.g., appealing to the same audience), the use is “at best, modestly transformative”.[25] This perspective creates a significant legal incentive for AI companies to pursue direct licensing agreements with major rights holders, a trend already being observed among developers like OpenAI and Microsoft.[1, 40]

Conclusion: The Systematic Resolution of the AI Ethics Crisis
The integration of licensing into artificial intelligence systems is not merely a technical adjustment but a fundamental reordering of the digital economy that prioritises human authorship, cultural integrity, and economic fairness. By analysing the music industry’s transition to streaming, we see that while distribution can be democratised, the erosion of gatekeeping must be replaced by robust, transparent frameworks for attribution and revenue sharing to avoid a “winner-take-all” collapse of the creative professions.[8, 9]
The ethical issues of clear attribution, real-time compliance, and fair compensation are solvable through the deployment of existing and emerging technologies. C2PA Content Credentials provide a cryptographically secure chain of provenance, while W3C ODRL enables the enforcement of semantic policies at the moment of content interaction.[5, 23] Blockchain and smart contracts offer the mechanical means to distribute micropayments, ensuring that the “value gap” is bridged and that creators are compensated for the role their data plays in the development of sophisticated AI models.[13, 14]
Furthermore, the protection of cultural heritage through community-governed licensing ensures that AI serves as a tool for revitalisation rather than misappropriation.[27] Embedding these rights management features directly into the tools—through forensic watermarking and signed manifests—creates a “trusted chain” that is significantly harder to bypass than traditional metadata.[28, 31]
As the legal landscape continues to evolve through 2025 and beyond, the move toward “compliance-by-design” will likely become the industry standard. AI developers who prioritise ethical data acquisition and transparent licensing will not only reduce their legal exposure but will also contribute to a healthier creative ecosystem where human and machine creativity can coexist. The strategic necessity of maintaining incentives for human authorship is clear: without a thriving human creative economy to provide high-quality “original” data, the future of artificial intelligence faces material risk of stagnation and model collapse.[41,42] Therefore, the infrastructure of integrity—built on licensing, provenance, and consent—is the only viable path forward for the artificial intelligence industry.
--------------------------------------------------------------------------------
1. Generative AI and Copyright - European Parliament, https://www.europarl.europa.eu/RegData/etudes/STUD/2025/774095/IUST_STU(2025)774095_EN.pdf
2. AI in the Cultural and Creative Industries, https://www.unesco.de/assets/dokumente/Deutsche_UNESCO-Kommission/02_Publikationen/DUK_Broschuere_KI_und_Kultur_EN_web_02.pdf
3. Sound AI Policy Demands Protecting Diverse Expression - The Illusion of More, https://illusionofmore.com/sound-ai-policy-demands-protecting-diverse-expression/
4. Why AI Opt-Out Systems Don’t Work | Copyright Alliance, https://copyrightalliance.org/why-opt-out-systems-do-not-work/
5. Compliance-by-Design Micro-Licensing for AI-Generated Content in ..., https://www.preprints.org/manuscript/202509.1968/v1
6. History of Music Streaming | Castr Blog, https://castr.com/blog/history-of-music-streaming/
7. The Impact of Streaming Platforms on the Music Industry: How ..., https://illustratemagazine.com/the-impact-of-streaming-platforms-on-the-music-industry-how-spotify-apple-music-and-others-have-changed-the-game/
8. Disrupting the Disrupters: Algorithmic Inequality in Music Streaming - Ravensbourne University London, https://www.ravensbourne.ac.uk/asset-bucket/prod/2020-10/Disrupting_the_Disrupters_MusicIndustry.pdf
9. How Streaming Changed The Music Industry - Atlanta Institute of Music, https://aimm.edu/blog/how-streaming-changed-the-music-industry/
10. The Re-Intermediation of the Music Industries Value ... - CREATe, https://www.create.ac.uk/wp-content/uploads/2022/03/CREATe-CMA-streaming-study-opinion-piece.pdf
11. What Is The Impact Of Streaming Services On The Music And Film Industries? - Consensus, https://consensus.app/questions/what-impact-streaming-services-music-film-industries/
12. https://www.lalal.ai/blog/how-much-streaming-services-pay-artists-in-2024/
13. Blockchain & AI use cases - AI and blockchain convergence - SettleMint Console, https://console.settlemint.com/documentation/blockchain-platform/knowledge-bank/blockchain-ai-usecases
14. AI-Driven Innovation in Cryptocurrency Payments - Rapyd, https://www.rapyd.net/blog/ai-driven-innovation-in-cryptocurrency-payments/
15. Gatekeeper of the Music World - UZH News - Universität Zürich, https://www.news.uzh.ch/en/articles/news/2024/streaming-platforms.html
16. AI, Authorship, and Copyright: A Comparison Between the United ..., https://international-and-comparative-law-review.law.miami.edu/ai-authorship-and-copyright-a-comparison-between-the-united-states-and-the-european-union/
17. Copyright Law in the Age of AI: Navigating Authorship, Infringement, and Creative Rights - New York State Bar Association, https://nysba.org/copyright-law-in-the-age-of-ai-navigating-authorship-infringement-and-creative-rights/
18. Why the Obsession with Human Creativity? A Comparative Analysis on Copyright Registration of AI-Generated Works - Harvard Law School Student Organizations, https://orgs.law.harvard.edu/halo/2025/02/21/why-the-obsession-with-human-creativity-a-comparative-analysis-on-copyright-registration-of-ai-generated-works/
19. Sounds of Science: Copyright Infringement in AI Music Generator ..., https://scholarship.law.edu/cgi/viewcontent.cgi?article=1108&context=jlt
20. AI created a song mimicking the work of Drake and The Weeknd. What does that mean for copyright law?, https://hls.harvard.edu/today/ai-created-a-song-mimicking-the-work-of-drake-and-the-weeknd-what-does-that-mean-for-copyright-law/
21. Court Rules AI Training on Copyrighted Works Is Not Fair Use — What It Means for Generative AI - Davis+Gilbert LLP, https://www.dglaw.com/court-rules-ai-training-on-copyrighted-works-is-not-fair-use-what-it-means-for-generative-ai/
22. Authors Guild Supports New Fairly Trained Licensing Model to Ensure Consent in Generative AI Training, https://authorsguild.org/news/ag-supports-fairly-trained-ai-licensing-model/
23. C2PA and Content Credentials Explainer :: C2PA Specifications, https://spec.c2pa.org/specifications/specifications/2.2/explainer/Explainer.html
24. Content Credentials : C2PA Technical Specification, https://spec.c2pa.org/specifications/specifications/2.2/specs/C2PA_Specification.html
25. Copyright Office Weighs In on AI Training and Fair Use | Skadden, Arps, Slate, Meagher & Flom LLP, https://www.skadden.com/insights/publications/2025/05/copyright-office-report
26. Artificial Intelligence and Indigenous Cultural Appropriation: Legal Challenges and Emerging Protections - American Bar Association, https://www.americanbar.org/groups/international_law/resources/newsletters/artificial-intelligence-indigenous-cultural-appropriation/
27. The Future of AI-Driven Cultural Heritage? — Mimeta, https://www.mimeta.org/mimeta-news-on-censorship-in-art/2025/3/12/is-now-the-future-of-ai-driven-cultural-heritage
28. Watermarking Software for Secure Collaboration - Steg.AI, https://steg.ai/products/leak-protection
29. Steg.AI Digital Watermarking | Patented Content Protection Technology, https://steg.ai/digital-watermarking/
30. Watermarking Software for Secure Collaboration - Steg.AI, https://steg.ai/watermarking-software/
31. Forensic Watermarking for Copyright Protection - Steg.AI, https://steg.ai/products/copyright-protection/
32. Prevent Content Leaks with Digital Watermarking | Steg.AI, https://steg.ai/products/leak-prevention-and-tracing/
33. C2PA Implementation Guidance, https://spec.c2pa.org/specifications/specifications/2.2/guidance/Guidance.html
34. Fairly Trained launches certification for generative AI models that respect creators’ rights, https://www.fairlytrained.org/blog/fairly-trained-launches-certification-for-generative-ai-models-that-respect-creators-rights
35. AI and the Fair Use Defense: Lessons from Two Recent Summary Judgment Rulings, https://www.fbm.com/publications/ai-and-the-fair-use-defense-lessons-from-two-recent-summary-judgment-rulings/
36. District Court Issues AI Fair Use Decision: Using Copyrighted Works to Train AI Models Is Fair Use, but Using Pirated Copies to Build a Central Library Is Not | Insights & Resources | Goodwin, https://www.goodwinlaw.com/en/insights/publications/2025/06/alerts-practices-aiml-district-court-issues-ai-fair-use-decision
37. AI Infringement Case Updates: July 7, 2025 - McKool Smith, https://www.mckoolsmith.com/newsroom-ailitigation-30
38. Fair use or free ride? The fight over AI training and US copyright law - IAPP, https://iapp.org/news/a/fair-use-or-free-ride-the-fight-over-ai-training-and-us-copyright-law
39. United States Copyright Office Weighs in on Fair Use Defense for Generative AI Training, https://www.mayerbrown.com/en/insights/publications/2025/05/united-states-copyright-office-weighs-in-on-fair-use-defense-for-generative-ai-training
40. Training Generative AI Models on Copyrighted Works Is Fair Use, https://www.arl.org/blog/training-generative-ai-models-on-copyrighted-works-is-fair-use/
41. Shumailov, I. et al., The Curse of Recursion: Training on Generated Data Makes Models Forget (arXiv:2305.17493, 2023; revised 2024), https://arxiv.org/abs/2305.17493. arXiv+1
42. Shumailov, I. et al., AI models collapse when trained on recursively generated data, Nature (2024), DOI: 10.1038/s41586-024-07566-y, https://www.nature.com/articles/s41586-024-07566-y.